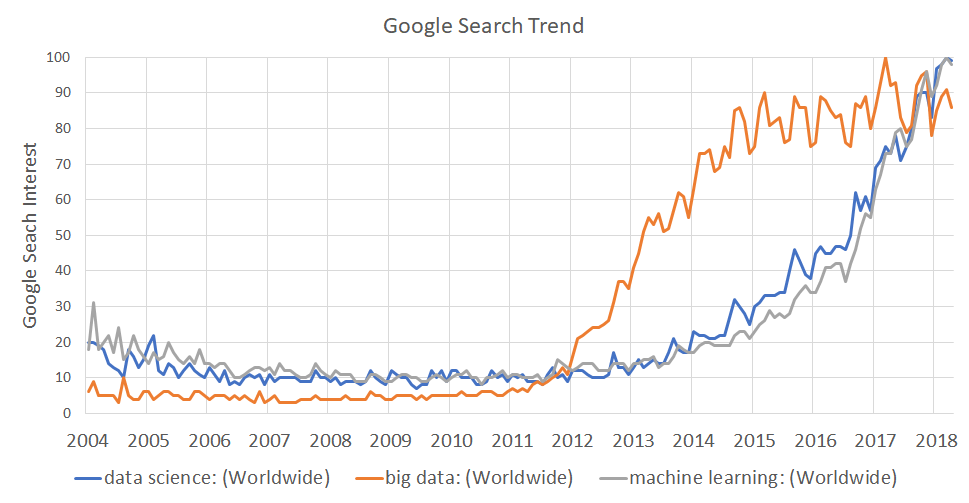
Starting around 2012, interest in data science has exploded as the graph below of monthly searches for data science, ‘big data’, or ‘machine learning’ shows. Providers of data science products and services often point to the explosion of big data as the cause of this interest, quoting cognitively incomprehensible stats such as our daily production of 2.5 quintillion bytes of data, and assert that it is this mass of data that necessitates data science and by extension us as data scientists. After all, how else are you going to monetize all that valuable info in those 500 million tweets sent yesterday?
But our society’s increasing reliance on technologies which insists upon being eternal witness to our digital alter egos is only partially the blame for why the world has gone data science crazy lately. And here’s why. Data science’s core value proposition ultimately has little to do “big data,” but rather is about the ability to extract insight from data (large or small). Hence, at its core, data science’s value is centered about the algorithms we apply to data. Algorithms which are complex and require hundreds to thousands of lines code to implement correctly. Prior to the recent maturing of open source options like R and Python, we were left with two bad options: spending countless hours implementing the models ourselves or paying for very expensive commercial implementations like MATLAB or SAS.
Now this wouldn’t have been that big an issue, IF we knew that the required temporal and financial investment would pay off. But therein lay the issue. Data science is an inherently exploratory endeavor and in the majority of cases, one cannot know if useful and relevant information is even contained in the data until a number of techniques and models have been attempted and compared. The problem of course is that in a business context, that’s a very hard sell to make (unless you work at Google).
Hence, we toiled in the darkness till at last, there pierced a ray of light that was R…soon followed by the serpent of goodness that is Python. Which leads us to the happy state we find ourselves today, where data exploration and modeling has never been easier. Need to create a linear regression? Two lines of code. What about a neural network? That’s five lines.
Now having written my own linear algebra library in C++, all I can say is this is f***ing awesome! Now when I want to test a new model on some data, I just mozy on over to Google and in an hour or two I have a preliminary prototype up and running.
However, as great as having all these high quality open source libraries is, there was an upside to not having them. And that was, if someone was doing data scientist, they probably knew what they were doing given they at least had to know the math/stats/algorithms well enough to implement them. With that barrier to entry removed, we’ve opened up the world of data science to a whole new segment of the population, which overall, I think is a good thing. But much like a chain saw, just because you can start the thing doesn’t mean you won’t cut your foot off with it if you’re not careful and know what you’re doing.
Like all forms of power, it comes with the risk of abuse. And today, given the hype of being a data scientist (remember it’s the sexiest job of the 21 century according to HBR), there’s a huge financial incentive for people to become “data scientists” after an introductory class in Python. And for companies that’s a problem. But I’ll end with a tip that can help. Whenever I interview a data scientist, I asked them to pick a model they’re very familiar with. Then I ask them to write out the sudo code on how to implement it. It never fails to weed out the posers 🙂