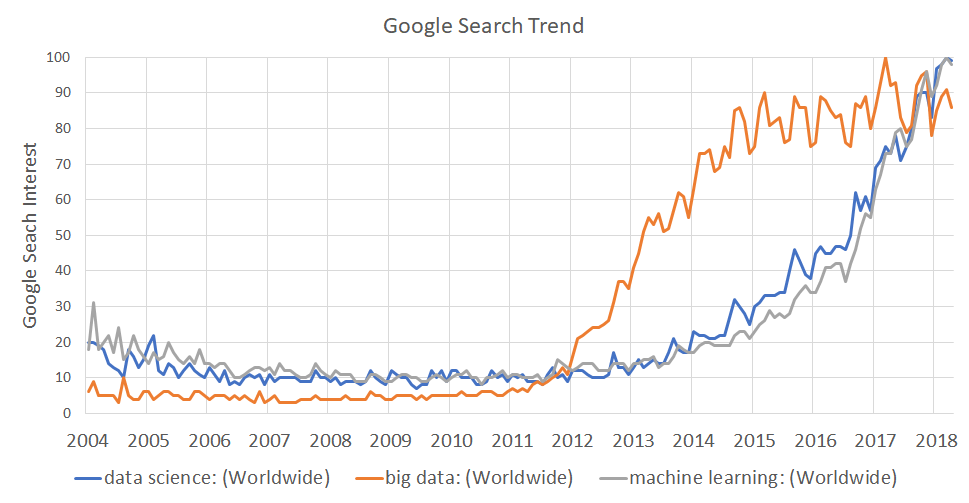
Today, data is the new oil. But oil needs to be refined to be usable and so does data. But what does that mean exactly? Well to answer that we need to take a slight detour and delve just a bit into the neuroscience of human cognition as it relates to processing and understanding information.
To begin though, let’s start with the big picture and ask why is data valuable in the first place? The simple answer is because data can inform your decisions and thereby improve their quality. Ok, cool… However, before that information can be leveraged there’s one minor detail that needs to happen and that is the information needs to get inside our heads.
But this is where we run into issues because there are two important facts about the brain you should know. First, your brain is vastly more powerful and complex than any computer in existence and by orders of magnitude. In fact, simulating just one second of brain activity took the 4th fast supercomputer a full 40 minutes. Thus, once the brain has data, it can do a lot with it, i.e. it’s pretty easy for your brain to make a good decision if it has the necessary information. However, getting information INTO the brain is another story.
You’ve probably heard that line about human working memory is only seven chunks (letters, digits, words, etc.) which is based on a study from 1956 by Miller. Turns out Miller was a little optimistic, given that the latest research indicates our true working memory capacity is closer to 3 – 5 chunks (on average we’ll just say four). Now why is this important? Simple. For most types of abstract information (like numbers) to be absorbed by the brain, they must pass through and be processed by our working memory system. So if you can only process four things at a time and you have a lot of numbers/data points, well that could take a while.
And to make matters worse, in any analysis you not only need to know what the numbers are but also need to understand how they relate to each other. e.g. knowing sales for the past four quarters is nice, but if you don’t know that each quarter was 20% lower than the last, you probably won’t be around long. But a relationship is also a thing, i.e. a chunk, which means it’s taking up one of those four slots in your working memory. So practically you’re really down to only 2 – 3 things.
At this point, it might seem as if we’ve run astray. Why are we talking working memory slots again? Because all the data in the world won’t help you make a better decision if it can’t be compressed into a series of bite sized chunks, each consisting of no more than 3 – 5 points that can be absorbed by our brains. And this is where the analytical tools of data science that allow you to reduce large amounts of data down to a few key points come in handy. In some sense, data science is just a data pre-processor which refines the oil that is raw data into the gasoline (insight) that our brains can run off of.